
Welcome
[February 2026] I am a Principal Engineering Manager at Microsoft.
As part of my role, I lead high-impact engineering and applied AI projects. My research spans the broader areas of Computer Vision, Machine Learning
and Large Language Models with a focus on Geospatial AI.
I received my Ph.D. in Computer Science from UCLA at the Vision Lab under the supervision of Stefano Soatto. My Ph.D. dissertation introduces sampling algorithms to handle nuisances in large-scale visual recognition. Previously, I received my diploma in Electrical and Computer Engineering from NTUA. I conducted my thesis with Petros Maragos and proposed Computer Vision algorithms for the digital restoration of the prehistoric Wall Paintings of Thera.
CV / LinkedIn / Google Scholar
I received my Ph.D. in Computer Science from UCLA at the Vision Lab under the supervision of Stefano Soatto. My Ph.D. dissertation introduces sampling algorithms to handle nuisances in large-scale visual recognition. Previously, I received my diploma in Electrical and Computer Engineering from NTUA. I conducted my thesis with Petros Maragos and proposed Computer Vision algorithms for the digital restoration of the prehistoric Wall Paintings of Thera.
CV / LinkedIn / Google Scholar
Selected Publications
MARS - A Foundational Map Auto-Regressor [paper]
Q. Zhang, S. Bag, R. Kukal, M. Figueroa, R. Madhok, N. Karianakis and F. Yu. International Conference on Learning Representations (ICLR), 2026.
Gemel: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge [paper]
A. Padmanabhan, N. Agarwal, A. Iyer, G. Ananthanarayanan, Y. Shu, N. Karianakis, G. H. Xu and R. Netravali. Symposium on Networked Systems Design and Implementation (NSDI), 2023.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers [paper]
R. Bhardwaj, Z. Xia, G. Ananthanarayanan, J. Jiang, Y. Shu, N. Karianakis, K. Hsieh, V. Bahl and I. Stoica. Symposium on Networked Systems Design and Implementation (NSDI), 2022.
SC-UDA: Style and Content Gaps aware Unsupervised Domain Adaptation for Object Detection [paper]
F. Yu, D. Wang, Y. Chen, N. Karianakis, T. Shen, P. Yu, D. Lymberopoulos, S. Lu, W. Shi and X. Chen. Winter Conference on Applications of Computer Vision (WACV), 2022.
BLT: Balancing Long-Tailed Datasets with Adversarially-Perturbed Images [paper]
J. Kozerawski, V. Fragoso, N. Karianakis, G. Mittal, M. Turk and M. Chen. Asian Conference on Computer Vision (ACCV), 2020.
HyperSTAR: Task-Aware Hyperparameters for Deep Networks [ORAL, paper, suppl]
G. Mittal, C. Liu, N. Karianakis, V. Fragoso, M. Chen and Y. Fu Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
Reinforced Temporal Attention and Split-Rate Transfer for Depth-Based Person Re-Identification [paper, code]
N. Karianakis, Z. Liu, Y. Chen and S. Soatto. European Conference on Computer Vision (ECCV), 2018.
An Empirical Evaluation of Current Convolutional Architectures' Ability to Manage Nuisance Location and Scale Variability [project, code]
N. Karianakis, J. Dong and S. Soatto. Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Multiview Feature Engineering and Learning [paper]
J. Dong, N. Karianakis, D. Davis, J. Hernandez, J. Balzer and S. Soatto. Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Visual Scene Representations: Scaling and Occlusion in Convolutional Architectures [paper]
S. Soatto, J. Dong and N. Karianakis. International Conference on Learning Representations (ICLR), workshop, 2015.
Boosting Convolutional Features for Robust Object Proposals [paper]
N. Karianakis, T. Fuchs and S. Soatto. arXiv preprint, 2015.
An integrated System for Digital Restoration of Prehistoric Theran Wall Paintings [paper]
N. Karianakis and P. Maragos. Conference on Digital Signal Processing (DSP), 2013.
Q. Zhang, S. Bag, R. Kukal, M. Figueroa, R. Madhok, N. Karianakis and F. Yu. International Conference on Learning Representations (ICLR), 2026.
Gemel: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge [paper]
A. Padmanabhan, N. Agarwal, A. Iyer, G. Ananthanarayanan, Y. Shu, N. Karianakis, G. H. Xu and R. Netravali. Symposium on Networked Systems Design and Implementation (NSDI), 2023.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers [paper]
R. Bhardwaj, Z. Xia, G. Ananthanarayanan, J. Jiang, Y. Shu, N. Karianakis, K. Hsieh, V. Bahl and I. Stoica. Symposium on Networked Systems Design and Implementation (NSDI), 2022.
SC-UDA: Style and Content Gaps aware Unsupervised Domain Adaptation for Object Detection [paper]
F. Yu, D. Wang, Y. Chen, N. Karianakis, T. Shen, P. Yu, D. Lymberopoulos, S. Lu, W. Shi and X. Chen. Winter Conference on Applications of Computer Vision (WACV), 2022.
BLT: Balancing Long-Tailed Datasets with Adversarially-Perturbed Images [paper]
J. Kozerawski, V. Fragoso, N. Karianakis, G. Mittal, M. Turk and M. Chen. Asian Conference on Computer Vision (ACCV), 2020.
HyperSTAR: Task-Aware Hyperparameters for Deep Networks [ORAL, paper, suppl]
G. Mittal, C. Liu, N. Karianakis, V. Fragoso, M. Chen and Y. Fu Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
Reinforced Temporal Attention and Split-Rate Transfer for Depth-Based Person Re-Identification [paper, code]
N. Karianakis, Z. Liu, Y. Chen and S. Soatto. European Conference on Computer Vision (ECCV), 2018.
An Empirical Evaluation of Current Convolutional Architectures' Ability to Manage Nuisance Location and Scale Variability [project, code]
N. Karianakis, J. Dong and S. Soatto. Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Multiview Feature Engineering and Learning [paper]
J. Dong, N. Karianakis, D. Davis, J. Hernandez, J. Balzer and S. Soatto. Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Visual Scene Representations: Scaling and Occlusion in Convolutional Architectures [paper]
S. Soatto, J. Dong and N. Karianakis. International Conference on Learning Representations (ICLR), workshop, 2015.
Boosting Convolutional Features for Robust Object Proposals [paper]
N. Karianakis, T. Fuchs and S. Soatto. arXiv preprint, 2015.
An integrated System for Digital Restoration of Prehistoric Theran Wall Paintings [paper]
N. Karianakis and P. Maragos. Conference on Digital Signal Processing (DSP), 2013.
Theses
N. Karianakis.
Sampling Algorithms to Handle Nuisances in Large-Scale Recognition.
Ph.D. Dissertation, 2017 (University of California, Los Angeles) [pdf]
N. Karianakis.
Digital Restoration of Prehistoric Theran Wall Paintings.
Diploma Thesis, 2011 (National Technical University of Athens) [pdf (in Greek)]
Sampling Algorithms to Handle Nuisances in Large-Scale Recognition.
Ph.D. Dissertation, 2017 (University of California, Los Angeles) [pdf]
N. Karianakis.
Digital Restoration of Prehistoric Theran Wall Paintings.
Diploma Thesis, 2011 (National Technical University of Athens) [pdf (in Greek)]
Demos
J. Dong, X. Fei, N. Karianakis, K. Tsotsos and S. Soatto.
Visual-Inertial Scene Representations.
CVPR demo session, June 2016 [poster, demo]
Visual-Inertial Scene Representations.
CVPR demo session, June 2016 [poster, demo]
Posters
Reinforced Temporal Attention and Split-Rate Transfer for Depth-Based Person Re-Identification.
ECCV, September 2018 [pdf]
An Empirical Evaluation of Current Convolutional Architectures' Ability to Manage Nuisance Location and Scale Variability.
CVPR, June 2016 [pdf]
VL‐SLAM: Real‐Time Visual‐Inertial Navigation and Semantic Mapping.
CVPR demo, June 2016 [pdf]
Learning to Discriminate in the Wild: Representation-Learning Network for Nuisance-Invariant Image Comparison.
UCLA SEAS Tech Forum, February 2014 [pdf]
ECCV, September 2018 [pdf]
An Empirical Evaluation of Current Convolutional Architectures' Ability to Manage Nuisance Location and Scale Variability.
CVPR, June 2016 [pdf]
VL‐SLAM: Real‐Time Visual‐Inertial Navigation and Semantic Mapping.
CVPR demo, June 2016 [pdf]
Learning to Discriminate in the Wild: Representation-Learning Network for Nuisance-Invariant Image Comparison.
UCLA SEAS Tech Forum, February 2014 [pdf]
Internships
Summer 2016: Research intern in Microsoft Research at Redmond.
Our research on Person Re-identification from depth introduced a novel temporal-attention principle based on reinforcement learning (paper). Mentors: Zicheng Liu and Yinpeng Chen.
Summer 2015: R&D Engineering intern at Sony's Intelligent System Technology Dept. in Tokyo.
I designed and implemented deep reinforcement learning software for autonomous navigation. My role involved algorithmic design, implementation lead and experimentation on simulated and real data. Mentors: Yusuke Watanabe, Akira Nakamura and Kenta Kawamoto.
Summer 2014: Research intern in NASA's Jet Propulsion Laboratory.
We invented a novel algorithm for generic object proposals and large-scale detection (arXiv). Mentor: Thomas Fuchs.
Summer 2013: Research intern in the Computer Vision lab at Peking University in Beijing.
Research in graphical models with Computer Vision applications. Mentor: Yizhou Wang.
Our research on Person Re-identification from depth introduced a novel temporal-attention principle based on reinforcement learning (paper). Mentors: Zicheng Liu and Yinpeng Chen.
Summer 2015: R&D Engineering intern at Sony's Intelligent System Technology Dept. in Tokyo.
I designed and implemented deep reinforcement learning software for autonomous navigation. My role involved algorithmic design, implementation lead and experimentation on simulated and real data. Mentors: Yusuke Watanabe, Akira Nakamura and Kenta Kawamoto.
Summer 2014: Research intern in NASA's Jet Propulsion Laboratory.
We invented a novel algorithm for generic object proposals and large-scale detection (arXiv). Mentor: Thomas Fuchs.
Summer 2013: Research intern in the Computer Vision lab at Peking University in Beijing.
Research in graphical models with Computer Vision applications. Mentor: Yizhou Wang.
Research Projects
Reinforced Temporal Attention and Split-Rate Transfer for Depth-Based Person Re-Identification. [paper, code]
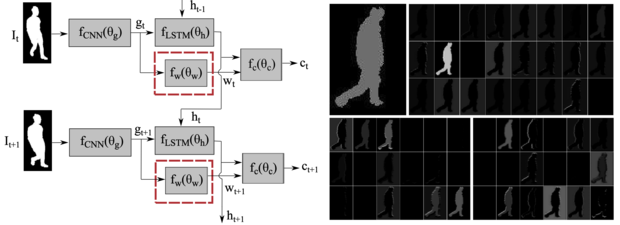
We address the problem of person re-identification from commodity depth sensors. One challenge for depth-based recognition is data scarcity. Our first contribution addresses this problem by introducing split-rate RGB-to-Depth transfer, which leverages large RGB datasets more effectively than popular fine-tuning approaches. Our transfer scheme is based on the observation that the model parameters at the bottom layers of a deep convolutional neural network can be directly shared between RGB and depth data while the remaining layers need to be fine-tuned rapidly. Our second contribution enhances re-identification for video by implementing temporal attention as a Bernoulli-Sigmoid unit acting upon frame-level features. Since this unit is stochastic, the temporal attention parameters are trained using reinforcement learning. Extensive experiments validate the accuracy of our method in person re-identification from depth sequences. Finally, in a scenario where subjects wear unseen clothes, we show large performance gains compared to a state-of-the-art model which relies on RGB data.
An Empirical Evaluation of Current Convolutional Architectures’ Ability to Manage Nuisance Location and Scale Variability. [paper, code, project]
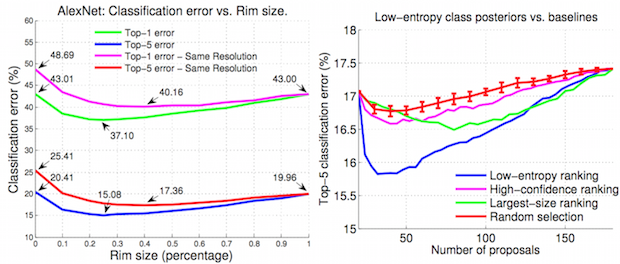
We conduct an empirical study to test the ability of convolutional neural networks (CNNs) to reduce the effects of nuisance transformations of the input data, such as location, scale and aspect ratio. We isolate factors by adopting a common convolutional architecture either deployed globally on the image to compute class posterior distributions, or restricted locally to compute class conditional distributions given location, scale and aspect ratios of bounding boxes determined by proposal heuristics. In theory, averaging the latter should yield inferior performance compared to proper marginalization. Yet empirical evidence suggests the converse, leading us to conclude that – at the current level of complexity of convolutional architectures and scale of the data sets used to train them – CNNs are not very effective at marginalizing nuisance variability. We also quantify the effects of context on the overall classification task and its impact on the performance of CNNs, and propose improved sampling techniques for heuristic proposal schemes that improve end-to-end performance to state-of-the-art levels. We test our hypothesis on a classification task using the ImageNet benchmark and on a wide-baseline matching task using the Oxford and Fischer’s datasets.
Boosting Convolutional Features for Robust Object Proposals. [paper]
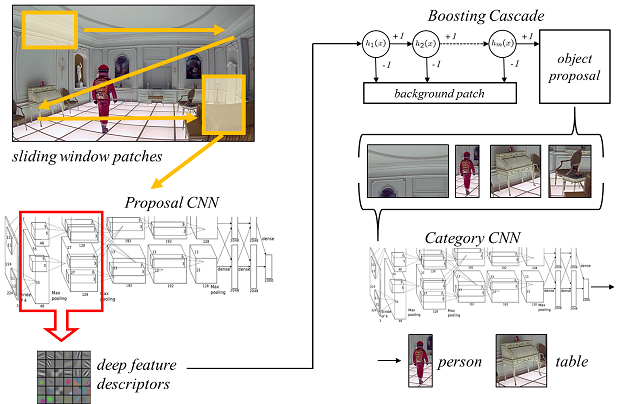
We present a method to generate object proposals, in the form of bounding boxes in a test image, to be fed to a classifier such as a convolutional neural network (CNN), in order to reduce test time complexity of object detection and classification. We leverage on filters learned in the lower layers of CNNs to design a binary boosting classifier and a linear regressor to discard as many windows as possible that are unlikely to contain objects of interest. We test our method against competing proposal schemes, and end-to-end on the Imagenet detection challenge. We show state-of-the-art performance when at least 1000 proposals per frame are used, at a manageable computational complexity compared to alternate schemes that make heavier use of low-level image processing.
Learning to Discriminate in the Wild: Representation-Learning Network for Nuisance-Invariant Image Comparison. [paper]

We test the hypothesis that a representation-learning architecture can train away the nuisance variability present in images, owing to noise and changes of viewpoint and illumination. First, we establish the simplest possible classification task, a binary classification with no intrinsic variability, which amounts to the determination of co-visibility from different images of the same underlying scene. This is the Occlusion Detection problem and the data are typically two sequential, but not necessarily consecutive or in order, video frames. Our network, based on the Gated Restricted Boltzmann machine (Gated RBM), learns away the nuisance variability appearing on the background scene and the occluder, which are irrelevant with occlusions, and in turn is capable of discriminating between co-visible and occluded areas by thresholding a one-dimensional semi-metric. Our method, combined with Superpixels, outperforms algorithms using features specifically engineered for occlusion detection, such as optical flow, appearance, texture and boundaries. We further challenge our framework with another Computer Vision problem, Image Segmentation from a single frame. We cast it as binary classification too, but here we also have to deal with the intrinsic variability of the scene objects. We perform boundary detection according to a similarity map for all pairs of patches and finally provide a semantic image segmentation by leveraging Normalized Cuts.
An Integrated System for Digital Restoration of Prehistoric Theran Wall Paintings. [paper]

We present a computer vision system for robust restoration of prehistoric Theran wall paintings, replacing or just supporting the work of a specialist. In the case of significant information loss on some areas of murals, the local inpainting methods are not sufficient for satisfactory restoration. Our strategy is to detect an area of relevant semantics, geometry and color in another location of the wall paintings, which in turn is stitched into the missing area by applying a seamless image stitching algorithm. An important part of our digital restoration system is the damaged and missing areas detector. It is used in combination with total variation inpainting at first for the missing area extraction and repair, and secondly for the elimination of minor defects on the retrieved part in the non-local inpainting mechanism. We propose a morphological algorithm for rough detection and we improve upon this approach by incorporating edge information. For missing areas with complicated boundaries we enhance the detection by using iterated graph cuts.
We address the problem of person re-identification from commodity depth sensors. One challenge for depth-based recognition is data scarcity. Our first contribution addresses this problem by introducing split-rate RGB-to-Depth transfer, which leverages large RGB datasets more effectively than popular fine-tuning approaches. Our transfer scheme is based on the observation that the model parameters at the bottom layers of a deep convolutional neural network can be directly shared between RGB and depth data while the remaining layers need to be fine-tuned rapidly. Our second contribution enhances re-identification for video by implementing temporal attention as a Bernoulli-Sigmoid unit acting upon frame-level features. Since this unit is stochastic, the temporal attention parameters are trained using reinforcement learning. Extensive experiments validate the accuracy of our method in person re-identification from depth sequences. Finally, in a scenario where subjects wear unseen clothes, we show large performance gains compared to a state-of-the-art model which relies on RGB data.
An Empirical Evaluation of Current Convolutional Architectures’ Ability to Manage Nuisance Location and Scale Variability. [paper, code, project]
We conduct an empirical study to test the ability of convolutional neural networks (CNNs) to reduce the effects of nuisance transformations of the input data, such as location, scale and aspect ratio. We isolate factors by adopting a common convolutional architecture either deployed globally on the image to compute class posterior distributions, or restricted locally to compute class conditional distributions given location, scale and aspect ratios of bounding boxes determined by proposal heuristics. In theory, averaging the latter should yield inferior performance compared to proper marginalization. Yet empirical evidence suggests the converse, leading us to conclude that – at the current level of complexity of convolutional architectures and scale of the data sets used to train them – CNNs are not very effective at marginalizing nuisance variability. We also quantify the effects of context on the overall classification task and its impact on the performance of CNNs, and propose improved sampling techniques for heuristic proposal schemes that improve end-to-end performance to state-of-the-art levels. We test our hypothesis on a classification task using the ImageNet benchmark and on a wide-baseline matching task using the Oxford and Fischer’s datasets.
Boosting Convolutional Features for Robust Object Proposals. [paper]
We present a method to generate object proposals, in the form of bounding boxes in a test image, to be fed to a classifier such as a convolutional neural network (CNN), in order to reduce test time complexity of object detection and classification. We leverage on filters learned in the lower layers of CNNs to design a binary boosting classifier and a linear regressor to discard as many windows as possible that are unlikely to contain objects of interest. We test our method against competing proposal schemes, and end-to-end on the Imagenet detection challenge. We show state-of-the-art performance when at least 1000 proposals per frame are used, at a manageable computational complexity compared to alternate schemes that make heavier use of low-level image processing.
Learning to Discriminate in the Wild: Representation-Learning Network for Nuisance-Invariant Image Comparison. [paper]
We test the hypothesis that a representation-learning architecture can train away the nuisance variability present in images, owing to noise and changes of viewpoint and illumination. First, we establish the simplest possible classification task, a binary classification with no intrinsic variability, which amounts to the determination of co-visibility from different images of the same underlying scene. This is the Occlusion Detection problem and the data are typically two sequential, but not necessarily consecutive or in order, video frames. Our network, based on the Gated Restricted Boltzmann machine (Gated RBM), learns away the nuisance variability appearing on the background scene and the occluder, which are irrelevant with occlusions, and in turn is capable of discriminating between co-visible and occluded areas by thresholding a one-dimensional semi-metric. Our method, combined with Superpixels, outperforms algorithms using features specifically engineered for occlusion detection, such as optical flow, appearance, texture and boundaries. We further challenge our framework with another Computer Vision problem, Image Segmentation from a single frame. We cast it as binary classification too, but here we also have to deal with the intrinsic variability of the scene objects. We perform boundary detection according to a similarity map for all pairs of patches and finally provide a semantic image segmentation by leveraging Normalized Cuts.
An Integrated System for Digital Restoration of Prehistoric Theran Wall Paintings. [paper]
We present a computer vision system for robust restoration of prehistoric Theran wall paintings, replacing or just supporting the work of a specialist. In the case of significant information loss on some areas of murals, the local inpainting methods are not sufficient for satisfactory restoration. Our strategy is to detect an area of relevant semantics, geometry and color in another location of the wall paintings, which in turn is stitched into the missing area by applying a seamless image stitching algorithm. An important part of our digital restoration system is the damaged and missing areas detector. It is used in combination with total variation inpainting at first for the missing area extraction and repair, and secondly for the elimination of minor defects on the retrieved part in the non-local inpainting mechanism. We propose a morphological algorithm for rough detection and we improve upon this approach by incorporating edge information. For missing areas with complicated boundaries we enhance the detection by using iterated graph cuts.